


Tóm tắt nhanh
- X-Robots-Tag là chỉ thị nằm trong HTTP response header, giúp kiểm soát việc index, follow hoặc hiển thị snippet của bot tìm kiếm.
- Nó đặc biệt hữu ích với file PDF, ảnh, trang động hoặc mọi URL mà bạn không muốn sửa trực tiếp trong HTML.
- X-Robots-Tag không thay thế robots.txt, canonical hay 301; mỗi công cụ giải quyết một vấn đề khác nhau.
X-Robots-Tag là cách gắn tín hiệu noindex, nofollow hoặc noarchive ở cấp HTTP header, rất hữu ích khi bạn cần kiểm soát index mà không muốn sửa trực tiếp HTML của từng trang. Nếu đang dọn cấu trúc website, hãy coi nó là một phần của bộ công cụ technical SEO chứ không phải mẹo riêng lẻ.
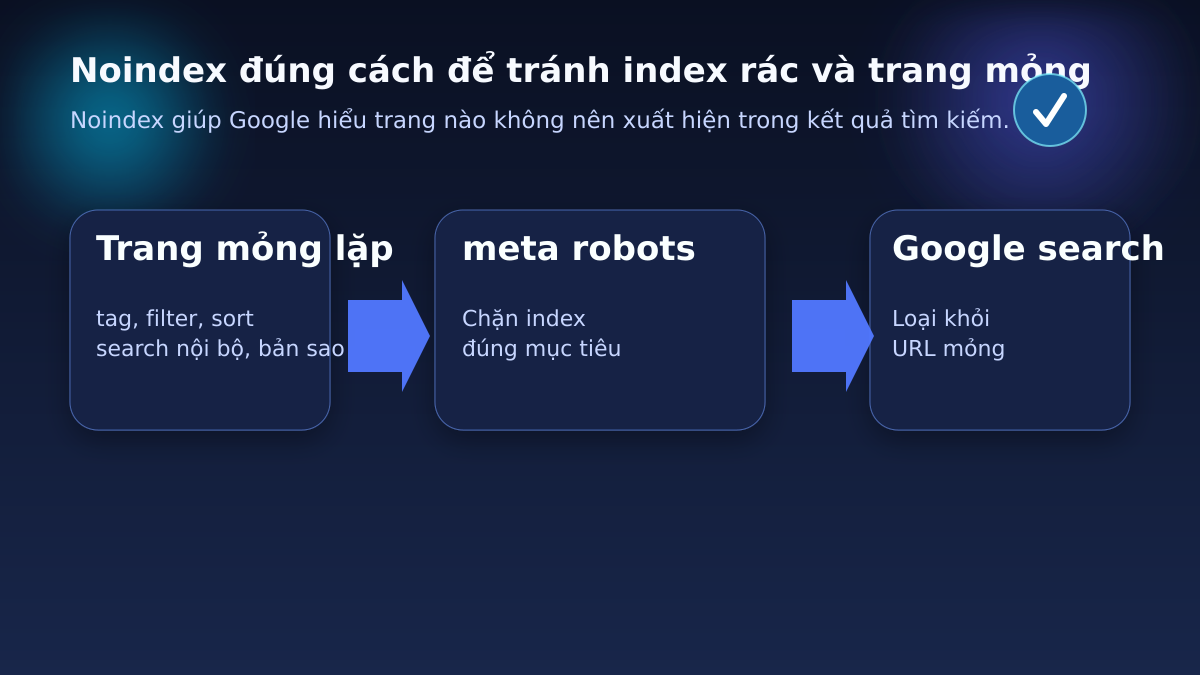
X-Robots-Tag là gì?
X-Robots-Tag là một chỉ thị dành cho công cụ tìm kiếm được truyền qua HTTP header. Nói đơn giản, thay vì đặt quy tắc trong mã HTML của trang, bạn gửi quy tắc ngay ở phản hồi của server. Khi bot đọc header đó, nó hiểu cách xử lý URL: có index hay không, có follow liên kết hay không, và có nên hiển thị snippet hay không.
Đây là lý do X-Robots-Tag rất hữu ích khi bạn làm việc với file PDF, hình ảnh, tài nguyên được sinh động bởi ứng dụng, hoặc các trang mà việc chỉnh HTML không thuận tiện. Nếu bạn đang tìm cách hiểu nền tảng kỹ thuật tổng thể, nên đọc song song bài Technical SEO là gì? và Google Search Console là gì? để thấy header này nằm ở đâu trong bức tranh crawl và index.
Ví dụ phổ biến nhất là header `X-Robots-Tag: noindex, follow`. Cấu hình này nói với bot rằng trang không nên vào chỉ mục, nhưng liên kết trên trang vẫn có thể được theo dõi. Trong thực tế, đây là lựa chọn thường gặp cho các trang mỏng, trang tạm, file đính kèm hoặc nội dung chỉ phục vụ vận hành.
Khi nào nên dùng X-Robots-Tag?
Không phải URL nào ít traffic cũng nên gắn noindex. Bạn chỉ nên dùng X-Robots-Tag khi trang đó có lý do rõ ràng để tồn tại trên website nhưng không cần đại diện cho một truy vấn tìm kiếm. Nếu dùng bừa, bạn rất dễ tự làm mất các trang có thể tối ưu thành landing page hoặc trang hỗ trợ chuyển đổi.
- File PDF, tài liệu tải xuống hoặc tài nguyên mà bạn không muốn sửa HTML bên trong.
- Trang lọc, trang kết quả nội bộ, trang tạm hoặc trang dùng cho vận hành kỹ thuật.
- Trang động tạo bởi hệ thống mà việc chèn meta robots vào từng template rất khó bảo trì.
- Các tình huống cần chặn index ở cấp server hoặc CDN thay vì chỉnh từng trang thủ công.
X-Robots-Tag khác meta robots, robots.txt và canonical thế nào?
Bốn khái niệm này thường bị dùng lẫn với nhau, trong khi mỗi cái giải quyết một câu hỏi khác nhau. Nếu bạn chỉ nhớ một điều, hãy nhớ rằng: robots.txt nói về crawl, X-Robots-Tag và meta robots nói về cách bot xử lý phản hồi, còn canonical nói về việc chọn URL chuẩn khi có nội dung gần giống.
Nếu mục tiêu của bạn là xử lý nội dung trùng lặp, bài Canonical Tag là gì? sẽ giúp bạn chọn URL chuẩn đúng cách. Nếu mục tiêu là giảm chỉ mục cho các URL không cần xuất hiện trên SERP, bạn nên đọc thêm Noindex là gì? và Robots.txt là gì? để không nhầm lẫn giữa chặn crawl và chặn index.
| Công cụ | Nằm ở đâu | Tác động chính | Khi nào dùng |
|---|---|---|---|
| X-Robots-Tag | HTTP response header | Kiểm soát index/follow/snippet cho một phản hồi | Khi không muốn sửa HTML hoặc cần áp dụng ở cấp server/CDN |
| Meta robots | Trong HTML | Kiểm soát index/follow/snippet cho trang HTML | Khi bạn chỉnh được template hoặc nội dung trang |
| Robots.txt | Tệp robots.txt | Hướng dẫn bot có được crawl đường dẫn hay không | Khi muốn giảm crawl URL rác hoặc khu vực không cần thu thập |
| Canonical | Thẻ rel=canonical | Chọn URL chuẩn cho nội dung gần/trùng | Khi có biến thể URL, tham số, bản sao hoặc trang gần giống |
| 301 Redirect | Header phản hồi / rule redirect | Chuyển hẳn sang URL mới | Khi đổi slug, gộp bài hoặc di chuyển nội dung |
Ví dụ cấu hình X-Robots-Tag trong thực tế
Bạn không cần biết hết mọi nền tảng để hiểu cách dùng. Điều quan trọng là nắm nguyên tắc: server gửi header trước khi bot đọc nội dung, và bot ra quyết định dựa trên header đó.
Apache
Header set X-Robots-Tag "noindex, follow"Nginx
add_header X-Robots-Tag "noindex, follow" always;Kiểm tra nhanh bằng terminal
curl -I https://example.com/duong-dan-can-chanNếu website của bạn đi qua CDN hoặc WAF, hãy kiểm tra ở tầng nào header được gắn. Đôi khi origin server đã đúng nhưng cache ở CDN vẫn giữ phiên bản cũ, khiến bot hoặc người dùng chưa thấy thay đổi. Trong những trường hợp như vậy, bạn cần xác nhận header bằng response thực tế, không chỉ nhìn vào file cấu hình.
Với WordPress, X-Robots-Tag thường được gắn qua plugin SEO, rule của server hoặc hook ở tầng ứng dụng. Nếu bạn chỉ muốn chặn index cho một số trang, nhưng vẫn muốn các trang khác hoạt động bình thường, hãy ưu tiên cách áp dụng theo mẫu/loại trang thay vì áp dụng toàn site.
Những lỗi thường gặp khi dùng X-Robots-Tag
Lỗi gây hại nhất thường không phải lỗi kỹ thuật phức tạp, mà là nhầm mục tiêu. Khi một trang cần giảm index, noindex là tín hiệu phù hợp hơn robots.txt; khi một trang chỉ cần hợp nhất tín hiệu về URL chuẩn, canonical mới là lựa chọn chính. Nếu cần chuyển hẳn người dùng và bot sang URL khác, 301 redirect mới là giải pháp đúng.
- Gắn noindex nhưng đồng thời chặn luôn bằng robots.txt, khiến Google không còn cơ hội đọc tín hiệu noindex.
- Áp dụng header quá rộng, ví dụ vô tình chặn cả trang hữu ích hoặc toàn bộ thư mục blog.
- Không kiểm tra response header sau khi triển khai, dẫn tới tưởng là đã sửa nhưng bot vẫn thấy bản cũ.
- Quên theo dõi cache của CDN, WAF hoặc plugin cache, làm thay đổi chưa phản ánh ngay trên live page.
- Nhầm X-Robots-Tag với canonical, trong khi canonical không chặn index mà chỉ hướng bot chọn URL chuẩn.
Cách kiểm tra X-Robots-Tag đã hoạt động chưa
Sau khi gắn header, hãy kiểm tra ở cấp HTTP response thay vì chỉ nhìn vào giao diện website. Bot không đọc bài như con người; nó đọc phản hồi mà server trả về.
- Dùng `curl -I` hoặc công cụ tương tự để xem response headers.
- Kiểm tra xem header có thực sự xuất hiện trên URL mục tiêu hay không.
- Mở Google Search Console để xem URL Inspection và trạng thái index cập nhật thế nào.
- Theo dõi lại sau một vài lần crawl để tránh kết luận quá sớm khi Google chưa ghé lại.
Nếu URL đó thuộc một cụm nội dung lớn hơn, hãy đối chiếu với Crawl budget là gì? để hiểu vì sao Google chưa cập nhật ngay. Một website có quá nhiều URL rác, tham số hoặc trang mỏng sẽ làm quá trình crawl lại chậm hơn bạn mong đợi.
Khi cần dọn URL cũ hoặc đổi cấu trúc, đừng quên bài 301 Redirect là gì? vì nhiều trường hợp người làm SEO chọn nhầm giữa noindex, canonical và redirect. Mỗi công cụ có một vai trò khác nhau trong quản trị index và tín hiệu SEO.
FAQ
X-Robots-Tag có thay thế robots.txt không?
Không. Robots.txt kiểm soát crawl theo đường dẫn, còn X-Robots-Tag kiểm soát cách bot xử lý một phản hồi cụ thể. Hai thứ thường đi cùng nhau, nhưng không thay thế nhau.
X-Robots-Tag khác meta robots thế nào?
Meta robots nằm trong HTML của trang, còn X-Robots-Tag nằm trong header HTTP. Nếu bạn không thể hoặc không muốn chèn trực tiếp vào HTML, header là cách linh hoạt hơn.
Bao lâu Google sẽ bỏ URL khỏi index sau khi thêm noindex?
Không có mốc cố định. Thời gian phụ thuộc vào tốc độ crawl lại của Google, tần suất cập nhật nội dung và việc trang đó có còn được liên kết nội bộ hay không.
Cần rà soát X-Robots-Tag, noindex và technical SEO cho website?
Nếu bạn muốn kiểm tra header, noindex, robots.txt, canonical và cấu trúc index của website một cách bài bản, hãy xem dịch vụ SEO hoặc đặt một SEO audit để xác định URL nào nên index, URL nào nên chặn và URL nào nên hợp nhất.


